
|
Fudan University
|
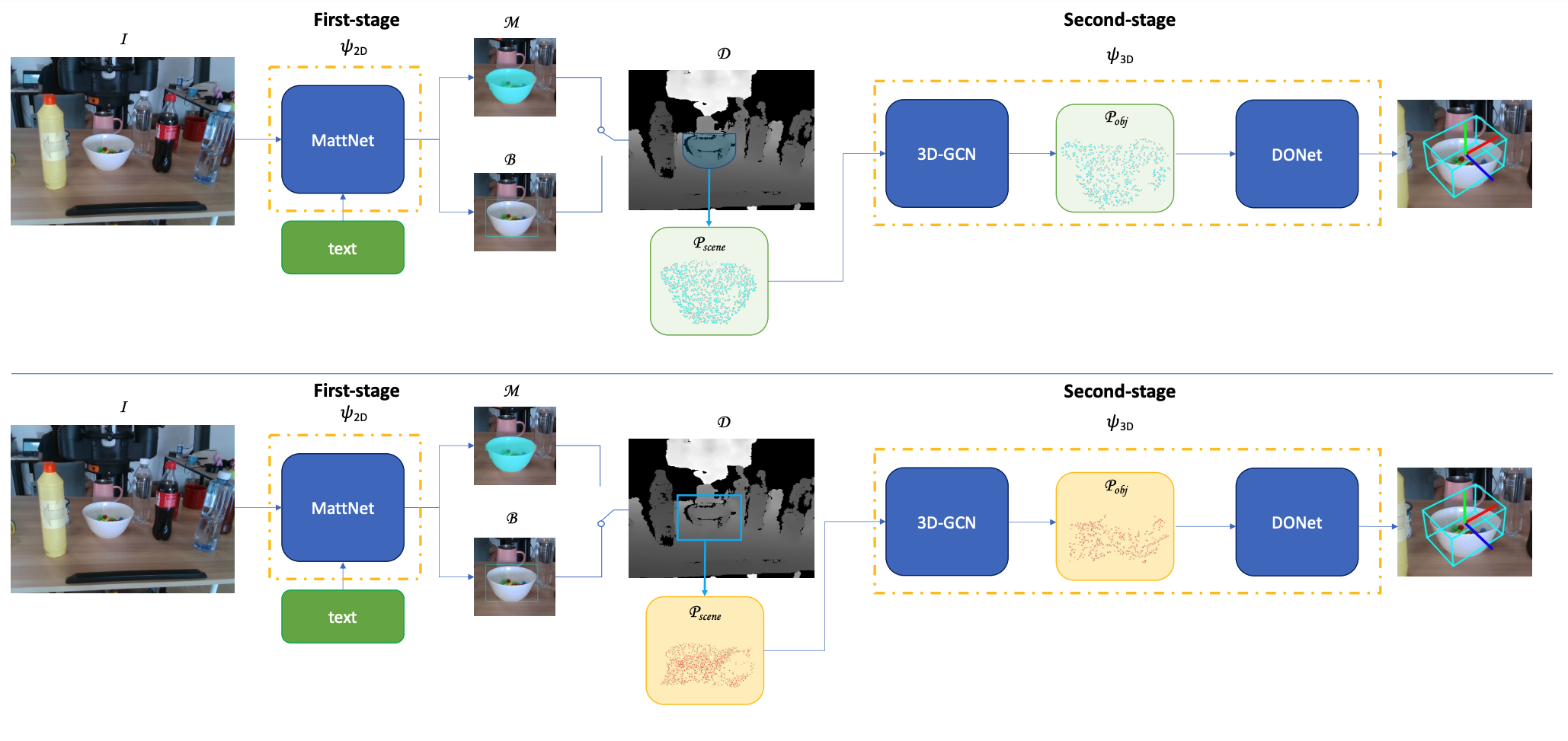
This paper studies the task of any objects grasping from the known categories by free-form language instructions. This task demands the technique in computer vision, natural language processing, and robotics. We bring these disciplines together on this open challenge, which is essential to human-robot interaction. Critically, the key challenge lies in inferring the category of objects from linguistic instructions and accurately estimating the 6-DoF information of unseen objects from the known classes. In contrast, previous works focus on inferring the pose of object candidates at the instance level. This significantly limits its applications in real-world scenarios.In this paper, we propose a language-guided 6-DoF category-level object localization model to achieve robotic grasping by comprehending human intention. To this end, we propose a novel two-stage method. Particularly, the first stage grounds the target in the RGB image through language description of names, attributes, and spatial relations of objects. The second stage extracts and segments point clouds from the cropped depth image and estimates the full 6-DoF object pose at category-level. Under such a manner, our approach can locate the specific object by following human instructions, and estimate the full 6-DoF pose of a category-known but unseen instance which is not utilized for training the model. Extensive experimental results show that our method is competitive with the state-of-the-art language-conditioned grasp method. Importantly, we deploy our approach on a physical robot to validate the usability of our framework in real-world applications. Please refer to the supplementary for the demo videos of our robot experiments.

|
C. Cheang,H. Lin, Y. Fu, X. Xue
Learning 6-DoF Object Poses to Grasp Category-Level Objects by Language ICRA 2022. [arXiv] |
Videos |
|
|

Acknowledgements
The website is modified from this template.
|